https://gall.dcinside.com/mgallery/board/view/?id=visualarts&no=5156
미연시 한패에 관한 짧은 노하우 - 비주얼 아츠 갤러리
요즘 한패 하시는 분들도 많고 하니, 앞으로 더 많은 사람들이 한패를 성공시킬 수 있도록 짧은 지식이나마 공유해 볼까함참고로 본인은 이제 갓 30대 들어설락 말락 하는 6년차 프로그래먼데,
gall.dcinside.com
다른 분이 정리하셨었던 글을 나중에 발견해 공유합니다.
제 글과 기본적인 골자는 같습니다만, 윗글이 좀 더 깔끔히 정리되어 있는 느낌입니다.
윗글을 먼저 보시고 이해가 안되신다면
아래에 제가 직접 하나하나 했던 과정을 보시는 게 이해에 더욱 도움이 되실 거라고 생각합니다.
글을 쓰기에 앞서 필자는 애니도 자막이 있어야 보고, 미연시도 번역기 돌려서 하는 일알못이며,
프로그래밍이라고는 헬로우 월드나 출력할 줄 아는 컴퓨터랑 전혀 상관없는 전공의 이과생임을 밝힙니다.
저는 관련 지식은 전혀 없는 수준이고, 한글화에 성공한것은 우연이 겹친 야매에 가깝습니다.
강의라고 하기엔 부끄러운 수준이지만,
혹시나 (일본어 게임)한글패치를 시도하시는 분이나 시도해보고 싶으신 분들에게 조금이나마 도움이 될까 싶어서 글을 작성합니다.
(특히 BGI엔진을 사용한 게임의 한글화를 시도하시는 분들께는 좋은 정보가 될 것 같습니다)
입대 전에 남는 시간에 뭘 할까 생각하며 평소처럼 미연시를 하다가,
일본어 공부를 할겸 한글패치를 제작해 보면 어떨까 생각이 들었습니다.
저 역시 이런 일본어 게임들을 처음 접한 것은 다른 분들이 만들어주신 한글 패치를 통해서였고,
이제 제가 나이가 어느정도 들고 그런 능력을 갖추었으니, 이번엔 제가 베풀 때라고 느꼈습니다.
어떤 작품으로 할까 생각하다가,
아끼고 아껴놨던 사쿠라의 시를 이번에 플레이 할 겸 한글패치를 만들기로 했죠.
하지만 막상 그렇게 마음을 먹어도, 초보자가 처음부터 시작하기에는 막막하더군요..
뭘 어떻게 시작해야 할 지도 모르겠고, 무엇보다 정보를 찾는 것이 어려웠습니다.
인터넷으로만 정보를 찾았는데, 대부분의 글들이 너무 기초적인 것이라 도움이 안되거나,
반대로 너무 어려워서 알아들을 수 없었습니다.
그렇게 몇 시간을 검색해서 많은 글들을 보고.. 제가 알게 된 한글패치 방법은 다음과 같습니다.
(이것은 제가 본 글로만 판단한 것이기 때문에 실제와는 어느 정도 다를 수 있습니다.)
먼저 한글패치 방법은 크게 두 종류로 나뉩니다.
1. 폰트가 내장되어 있는 경우
2. 폰트가 내장되어 있지 않은 경우
1번의 경우에는 게임 파일 내에 폰트 파일(그림)이 따로 있어서, 이 경우에 게임에서 문자를 표시하는 방법은,
예를 들어 'あいうえお' 라는 문장이 게임에서 나온다면
게임 파일 내부에서 각각 'あ' 'い' 'う' 'え' 'お' 라는 글자 그림을 가져와서 화면에 표시하는 식입니다 (아마)
그러니까 과정은
'あいうえお'라는 텍스트 출력 명령 →'あ' 'い' 'う' 'え' 'お' 라는 문자열을 파일에서 가져옴 → 'あいうえお'화면에 표시
이 순서로 되겠네요.
이 경우에 우리가 패치해주는 과정은 2번과정, 즉 가져오는 문자 파일을 직접 수정해버리는 겁니다.
그러니까 예를 들어서 あ' 'い' 'う' 'え' 'お' 그림 파일들을 '아' '이' '우' '에' '오' 이런식으로 바꿔버리는 식이죠.
그렇게 패치를 하면 과정은
'あいうえお'라는 텍스트 출력 명령 →'아' '이' '우' '에' '오' 라는 문자열을 파일에서 가져옴 → '아이우에오' 화면에 표시
이렇게 되겠네요.
물론 이렇게 직접적으로 일대일 대응을 시키는 것은 아니고,
가각간갇갈... 이렇게 해서 한글로 표현할 수 있는 몇천개의 문자를 일본어 문자열에 일대일 대응시키는 방식이라고 하네요. 세종대왕님 덕분에(?) 엄청나게 많은 수의 한자를 사용하는 일본어 문자열에 비해 한글문자열이 수가 더 적기 때문에 모두 일대일 대응을 시킬 수 있다고 합니다.
출력되는 파일 자체를 수정하는 것이기 때문에 프로그래밍적으로 머리를 싸맬 일은 없지만,
게임 파일 안에서 폰트 파일을 찾아내야 한다는 점이나,
문자열을 수정해야 한다는 점에서 노가다 성이 짙다고 할 수 있습니다.
(그리고 번역문을 일대일 대응 시킨 일본문자로 변환해줄 프로그램도 만들어야 합니다)
사실 이 경우는 제가 해보지 않아서 자세히는 잘 모릅니다만, 위에 설명한 것이 정확한 것은 아닐지라도 대강의 과정은 맞을겁니다.
2번의 경우(폰트가 내장되어 있지 않은 경우)는 조금 다릅니다.
이 경우에는 폰트를 게임 파일 내에서 불러오는 것이 아니라, 윈도우에서 불러옵니다.
따라서 폰트를 찾고 바꾸고 하는 노가다는 없습니다 (하고 싶어도 못합니다)
대신 프로그램을 뜯어서(?) 일본어 문자열을 가져오는 것을 한국어 문자열를 가져오게(출력하게) 바꿔주어야 합니다.
이 경우는 저의 경험대로, 처음부터 어떻게 제가 했는지 적도록 하겠습니다.
그게 더 설명이 쉽고 초보자 분들에게도 도움이 될 것 같아서요.
저는 먼저 '사쿠라의 시'가 내부에 폰트를 가지고 있는지 아닌지 알아보려고 했습니다.
https://wiinemo.tistory.com/603
아마추어 한글화 강좌 3 - 헥스, 그리고 국가코드의 이해 (+ 고유코드)
[ 안 내 ] 관리자 허락 없이 해당 포스트의 내용을 외부 사이트에 업로드 하거나 배포하는 행위를 절대적으로 금합니다. 되도록이면 링크 주소를 이용해주시기 바랍니다. 상세 공지 참조 ▷ http://wiinemo.tistor..
wiinemo.tistory.com
그런데 위 글(위네모님)에 따르면
"
(다만, PC용 일본어 게임의 경우만 예외로 Window 폰트가 한글을 지원하기 때문에 어셈블리를 통해서, 실행파일에서 사용하는 국가코드를 'Shift-JIS'에서 'EUC-KR'로 바꿔주면 위에 말대로 '스크립트' 번역만하여 입력하면 끝나게 된다..)
"
라고 하네요. PC용 게임은 모두 윈도우에서 폰트를 가져오나 봅니다.
(이것 말고도 여러가지 기초를 배우는데 위 글이 도움이 되었습니다)
이제 제 경우가 2번이라는 것을 알았으니, 행동을 시작할 때입니다.
먼저 해야겠다고 생각한 것은 당연하게도 게임 데이터 파일의 압축을 푸는 일이었습니다.
게임 스크립트는 TXT파일로 존재하는 경우도 있겠지만, 보통의 경우에는 쉽게 편집 할 수 없는 압축된 형태로 존재합니다.

우선 텍스트(스크립트) 파일이 어디 있는지 알아야 뭘 하든 말든 하겠죠.
사쿠라의 시는 BGI엔진을 사용하고 있습니다.
다행히 인터넷에 검색해보니 관련 툴이 나왔습니다.
https://github.com/xmoeproject/BGITool
xmoeproject/BGITool
Tools work with BGI VN engine. Contribute to xmoeproject/BGITool development by creating an account on GitHub.
github.com
(위 링크 말고도 수많은 툴들이 있었습니다)
미연시는 정말 특수한 경우가 아니라면 대부분 다 알려진 엔진을 사용하기 때문에,
검색해보면 누군가 이미 만들어놓은 툴이 나올 수도 있다는 생각이 드네요.
아무튼 저는 저 툴을 사용하여 일단 닥치는 대로 신나게 압축을 다 풀어보았습니다.
첫 번째 파일 data01100에 바로 들어있더군요. data01***파일들이 다 스크립트 파일이더군요.
그것을 안 것은 파일명으로도 거의 유추할 수 있었지만,

크리스탈 타일 같은 프로그램으로 직접 (일본어 코드로)열어봐도 확인할 수 있습니다.
위 링크의 툴으로 TXT 파일로 변환했더니 영어 기준 툴이라 그런지 글자가 깨지더군요.
다행히도 한국분(길을걷다님)이 올려주신 툴이 있었습니다.
https://blog.naver.com/skyborrow/198358644
グリーングリーン OVERDRIVE EDITION 도구
OVERDRIVE사의 작품은 초전격 스트라이커 때부터 분석을 시작했지만 많은 난관에 부딪혀서 이제야...
blog.naver.com
(이분이 올려주신 COREA-BGI 툴로 한글실행, 출력까지 됐다면 참 좋았겠습니다만, 제작사가 달라서 그런지 되진 않더군요)
이제 저는 게임 파일 압축을 풀었고, 스크립트 파일을 찾았습니다. 그리고 그것을 수정, 리팩(재압축)하는 툴도 있습니다.
하지만 이 상태로 스크립트 파일에 한글을 입력해서 수정한다고 해도 게임을 실행하면 ???같은 식으로 제대로된 문자가 나오지 않습니다.
왜냐하면 지금 게임은 일본어를 가져와서 출력해주고 있기 때문에 한글을 넣는다고 해서 알아보지 못합니다.
(마치 일본사람에게 한국어로 아무리 열심히 설명해도 못알아듣는것과 같습니다)
더 자세하게 설명하자면 코드값이 달라서 입니다.
컴퓨터가 받아들이는 것은 오로지 숫자값입니다. 이 숫자를 어떻게 문자로 해석하느냐, 이것이 각 나라마다 다릅니다.
예를 들어, 일본 문자열(문자표)로 'あ'는 82A0입니다. (82A0이라는 숫자를 일본 컴퓨터가 'あ'라고 읽습니다)
하지만 82A0는 한국에서는 '궇'입니다.
그러니 'あ'라고 문자를 나타내는 일본 프로그램을 한국어로 실행한다면 '궇'이라고 나올 것입니다.
이것은 당연히 반대의 경우도 마찬가지로, 내가 입력한 것과 출력되는 것이 전혀 다르게 됩니다.
따라서 컴퓨터가 지금 사용하고 있는 문자코드표(문자 인코딩)을 일본에서 한국으로 바꿔줄 필요가 있습니다.
그건 알았지만 대체 어떻게 바꾸는걸까..
또 다시 인터넷 정보의 바다를 헤매고..
어딘가에서 디버거로 Create font 함수를 찾아서 charset값을 80에서 81로 바꾸면 된다는 정보를 찾았습니다.
아마 charset값이 80이면 일본이고 81이면 한국인가 봅니다.
당장 올리디버거로 exe파일을 실행해서 Ctrl+n으로 create font 함수를 검색해봤습니다.


밑에 두개 먼저 보자면,


오른쪽에 CharSet이라고 써있는 곳에 PUSH EAX라고 되있는게 보입니다.
아마 EAX값을 CharSet값으로 써라, 이런 말인 것 같습니다.
이 EAX값이 어디서 왔을까 보니, 바로 위에 AND EAX, 80이라는 줄이 보입니다.
80이라고 하니까 냄새가 납니다. 바로 이 값이 맞는 것 같습니다.
검색해보니 AND라는 명령어는 비교해서 같은값만 취한다? 뭐 그랬던 것 같은데
잘 모르겠고, 사실 인코딩 값을(단순한 숫자를) 넣어주는데 그렇게 복잡하게 하지는 않을 것 같으니
에라 모르겠다 그냥 80을 81로 바꿨습니다.

문제는 아까 찾았던 3개중 첫 번째입니다.
CharSet을 보니 아까랑 똑같이 PUSH EAX라고 되어있습니다.
그런데 EAX값을 찾으려고 아무리 눈을 씻고 찾아봐도 없습니다.
굉장히 위로 올라가면 등장하긴 하지만 무슨 영문모를 문장으로 쓰여있습니다.
어떻게 된걸까.. 한참을 고민했습니다만.
CharSet에서 세줄 올라가면 CALL BGI. 어쩌구 하는 문장이 있습니다.
CALL? 아래 있는 CreateFontA에도 CALL이라고 써있는 것을 보니 함수를 호출하는 말인 것 같습니다.
그렇다면 저 CALL BGI.00B5C030에서 함수를 가져와서 가져온 EAX값을 Charset에 넣어주는 것인가?
위치 00B5C030으로 갔습니다.

아래쪽에서부터 봐야겠죠. 함수가 끝나는 지점으로 내립니다.
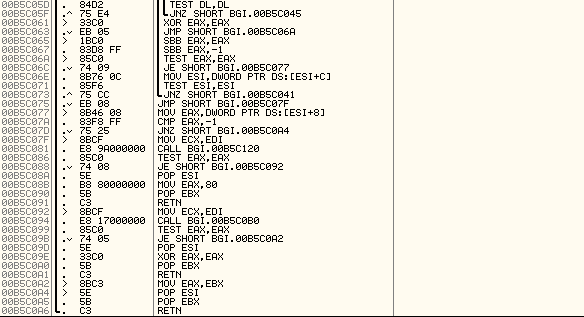
함수가 끝나는 곳으로 오니, MOV EAX,80이 보입니다!
저 80을 81로 바로 바꿔주고 되기를 기도하면서 게임을 실행해봅니다.
그런데 아차, 한국 로캘로는 게임이 실행자체가 안됩니다 ㅡㅡ;
일단 일본 로캘로 실행해봤더니 온통 뷁어로 나옵니다.
일단 한글이 나오기는 하는 걸로는 봐서 인코딩을 한국어로 변경하는 것은 성공한 듯 합니다.
이제 게임을 일본로캘뿐만 아니라 한국에서도 실행할 수 있게 하기만 하면 됩니다.
BGI 엔진 자체에서 한국 윈도우에서의 실행을 막고 있다고 생각해서 BGI엔진에 대해 검색해 보던 중,
코드 파인딩 프로젝트 268
[170428][Lump of Sugar] タユタマ2 -After Stories- 파인더의 한 마디: 타유타마2의 팬디스크 입니다. 가독성을 위해 텍스트에 테두리를 만드려면, 마지막 설정 스샷에 보이는 저 설정으로 바꾸면 됩니다. ...
capita.tistory.com
"
구버전 BGI엔진에서는 GetSystemDefaultLangID 함수로만 체크하던 것을, ... 이 함수들은 일본어라면 0x411을, 한국어라면 0x412를 뱉어내고, 이 값을 이용해 마지막 뒷자리가 11인지를 확인하는 작업을 합니다.
"
라고 하네요. (자본주의자님)
디버거를 실행해서 저 함수를 검색해보니

11이라는 값이 보이네요. 12라고 수정해 주었습니다.
그리고 실행했더니.. 실행이 됩니다!
하지만 어째서인지 아직도 글자가 깨집니다.. 그리고 뷁어가 아니라 완전히 듣도 보도 못한 이상한 문자들로 깨집니다.
대체 어째서일까? 여러가지 조건을 변경하며 원인을 찾던 중..
갗겦늏붹 이런 글자들은 깨지지 않고 잘 출력되는 것을 발견했습니다.
그리고 곧 이 글자들은 일본어 인코딩이 사용하는 주소와 같은 주소를 사용하는 한국 글자라는 것을 깨달았죠.
왜 이런 현상이 생기는지 여러 가설을 세우고 실험해봤지만..
결과적으로 해결을 한 것은 다음 글을 읽고나서 입니다.(두병더더님)
https://arallab.hided.net/board_codetalk/1979569
"
____________________________________________
바이너리 서치
8A 44 24 04 3C 80 73 03 33 C0 C3 3C A0 73 06 B8 01 00 00 00 C3 3C E0 1B C0 40 C3
_____________________________________________
두번째 수정할곳입니다.
왼쪽 화면에서 음영된 부분 0A0 > 오른쪽 화면처럼 0D0 로 변경한다.
2바이트중 상위바이트를 검사해서 A0 이상이면 1바이트를 유니코드로 변환시켜버린다.
일어는 9F FF 영역까지 쓰는것 같고 한글은 CF FF 영역까지 쓰는것 같더라. 그래서 요렇게 변시 시켜주니 잘된다..
"
아하. 딱 제가 겪고 있는 현상이었습니다.
일본어가 사용하고 있는 주소인 9F FF 까지의 한글만 출력하고 있던 것이죠.
저 바이너리와 완전히 같은 곳은 없었지만 비슷해 보이는 부분은 찾을 수 있었습니다. (A0 주변 바이너리)

그렇게 헥스 에디터로 그 부분의 A0을 D0으로 수정하자..

드디어 성공했습니다.
글로 쓰니 별 거 없는 과정이지만, 중간에 막히는 적이 굉장히 많았습니다.
막힐 때마다 아랄트랜스라는 훌륭한 툴이 있는 데 굳이 이걸 해야 할까.. 싶은 생각이 들었지만 오기로 해냈네요.
먼저 BGI엔진에 관해서 연구하신 분들이 있는것이 다행이었습니다. 모든 분께 감사를 표합니다.
그렇다고 해도 이거 하는데만 3일이 걸렸네요..
사실 한글이 나오게 하는건 이제 시작일 뿐인데 말이죠.. 역시 번역이라는 작업이 훨씬 시간이 많이 드니까요.
저도 할 수 있었으니 여러분들도 할 수 있을거예요. 의지만 있다면..
'미연시 > 한글화 강의' 카테고리의 다른 글
| 기본적인 한글패치 제작 방법 (미연시) ② (AdvHD/ws2 엔진) (6) | 2024.04.24 |
|---|---|
| 기본적인 한글패치 제작 방법 (미연시) ① (AdvHD/ws 엔진) (5) | 2022.12.26 |


댓글